
Deep learning is one of the most influential and rapidly advancing fields in artificial intelligence (AI) and machine learning (ML). It has revolutionized various industries by providing solutions to complex problems that were once thought to be unsolvable by machines. As a subset of machine learning, deep learning deals with algorithms that mimic the human brain’s functioning, learning patterns from vast amounts of data to make decisions, predictions, and classifications.
For professionals in many fields, particularly those involved in technology, research, and marketing, understanding deep learning’s mechanics, applications, and potential is increasingly crucial. This in-depth exploration will delve into what deep learning is, its structure, key components, historical evolution, applications across industries, and future directions.
What is Deep Learning?
Deep learning is a branch of machine learning based on artificial neural networks (ANN). While traditional machine learning relies on algorithms that are usually linear in their analysis and predictions, deep learning utilizes layers of neural networks to process data in more sophisticated and dynamic ways. These layers allow the model to extract and learn patterns from data, transforming raw input into usable information.
Neural networks simulate the functioning of the human brain, with layers of neurons (nodes) that communicate and pass information from one to the next. The more complex the network, the deeper the learning model becomes—hence the term “deep learning.”
A standard neural network is composed of the following key components:
• Input Layer: This is where the raw data is introduced into the system. For example, in image recognition, this could be pixel data from an image.
• Hidden Layers: These layers process the input data, extracting features and transforming it into something usable by the system. The “depth” of a neural network refers to the number of hidden layers it has. A deeper network can detect more complex patterns.
• Output Layer: This is where the final decision or prediction is made, based on the information processed in the hidden layers. For example, in an image recognition task, the output layer could classify the image as a “cat” or “dog.”
The strength of deep learning comes from its ability to learn and adapt using large volumes of data. As the model is exposed to more data, it refines its ability to recognize patterns and make predictions, becoming more accurate over time. This capacity for self-improvement has made deep learning a go-to tool in fields ranging from healthcare to finance.
A Brief History of Deep Learning
The roots of deep learning can be traced back to the early days of neural network research in the mid-20th century. While the concepts were developed decades ago, deep learning has only recently gained significant traction due to advancements in computational power and the availability of large datasets. Below is a brief timeline highlighting key milestones in deep learning’s evolution:
• 1943: Warren McCulloch and Walter Pitts laid the foundation for artificial neural networks by developing a model of artificial neurons that could simulate simple logical functions.
• 1958: Frank Rosenblatt introduced the perceptron, a single-layer neural network that could classify data into two categories. While limited in capability, this marked the first real application of neural networks.
• 1980s: The backpropagation algorithm, developed by Geoffrey Hinton, David Rumelhart, and Ronald J. Williams, solved the issue of training multi-layered neural networks. This breakthrough allowed for deeper networks, though the lack of computing power still restricted their practical use.
• 2006: The resurgence of interest in deep learning began with the work of Geoffrey Hinton, who demonstrated that deep neural networks could be effectively trained using unsupervised learning methods. This discovery reignited research and development in the field.
• 2012: A landmark moment came when Alex Krizhevsky, Ilya Sutskever, and Hinton’s team used a deep convolutional neural network (CNN) to win the ImageNet competition with unprecedented accuracy in image classification tasks. This moment is often seen as the true launch of the modern deep learning era.
• 2014-2018: During this period, deep learning models like Google’s DeepMind AlphaGo, OpenAI’s GPT series, and the development of deep reinforcement learning opened new avenues for AI applications, from game playing to natural language processing (NLP).
Today, deep learning forms the core of AI technologies powering autonomous systems, voice assistants, and various intelligent applications across industries.
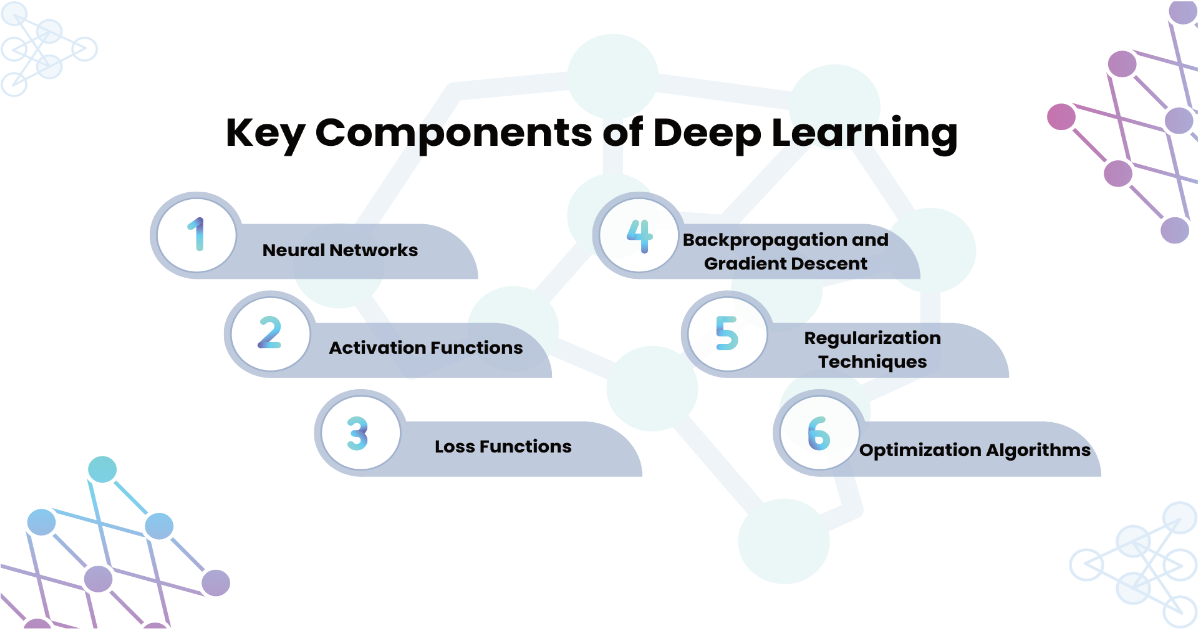
Key Components of Deep Learning
Deep learning systems are built on several key principles and components that enable them to learn and make predictions from data effectively. Below are some of the most critical concepts and techniques in deep learning:
1. Neural Networks
Neural networks are the foundation of deep learning. These networks consist of layers of interconnected nodes (or neurons), where each node processes data and passes it on to the next layer. Neural networks are inspired by the structure of the human brain, though they operate in a more simplified and mathematical manner.
a. Perceptron: A perceptron is the simplest type of neural network, consisting of a single neuron. It receives inputs, applies weights to these inputs, sums them, and then applies an activation function to generate an output.
b. Feedforward Neural Networks: In these networks, information flows in one direction—from the input layer, through hidden layers, to the output layer. There is no feedback loop, making these networks easier to train but limited in their capabilities.
c. Convolutional Neural Networks (CNNs): CNNs are particularly effective for processing grid-like data, such as images. They use convolutional layers to automatically detect features (e.g., edges, textures) in data, making them ideal for image recognition, video analysis, and even NLP tasks.
d. Recurrent Neural Networks (RNNs): RNN are specifically built to handle sequential data, like time series or natural language. These networks have loops that allow information to persist, enabling them to remember previous inputs. This makes RNNs particularly useful for tasks like speech recognition and text generation.
2. Activation Functions
An activation function is applied to each neuron’s output in a neural network, determining whether a neuron’s information should be passed to the next layer. Common activation functions include:
a. Sigmoid Function: Converts inputs into a value between 0 and 1, useful for binary classification tasks.
b. ReLU (Rectified Linear Unit): ReLU is a widely used activation function that returns the input if it’s positive; otherwise, it outputs zero.. ReLU helps solve the vanishing gradient problem, which occurs when the gradient used to update weights in backpropagation becomes very small.
c. Softmax Function: Converts a vector of values into probabilities, making it useful for multi-class classification tasks.
3. Loss Functions
A loss function quantifies the difference between the predicted output of the neural network and the actual target output. The goal of training is to minimize this loss, improving the network’s accuracy over time. Common loss functions include:
a. Mean Squared Error (MSE): Often used for regression tasks, this function calculates the average squared difference between predicted and actual values.
b. Cross-Entropy Loss: Commonly used in classification tasks, it compares the predicted probability distribution to the actual distribution.
4. Backpropagation and Gradient Descent
Backpropagation is the process of updating the weights in a neural network based on the error between the predicted output and the actual target. The gradients, or partial derivatives of the loss function with respect to each weight, are computed and then used to adjust the weights using the gradient descent algorithm.
Gradient Descent: This optimization algorithm minimizes the loss function by adjusting the weights in the direction that reduces the error. There are several variations, including stochastic gradient descent (SGD) and batch gradient descent, which differ in how they process data batches.
5. Regularization Techniques
Regularization techniques are used to prevent overfitting, which occurs when a model performs well on training data but poorly on unseen data. Common regularization methods include:
a. Dropout: A technique where random neurons are “dropped” or ignored during training, reducing the likelihood of the model becoming too reliant on specific neurons.
b. L2 Regularization: Adds a penalty to the loss function based on the size of the weights, encouraging the model to learn smaller, more general weights that are less likely to overfit.
6. Optimization Algorithms
Optimization algorithms are used to minimize the loss function and adjust the network’s parameters to improve performance. Beyond standard gradient descent, other advanced optimizers are:
a. Adam (Adaptive Moment Estimation): Adam is a widely used optimization algorithm that blends the benefits of AdaGrad and RMSProp. It dynamically adjusts the learning rate for each parameter, promoting faster convergence.
b. RMSProp (Root Mean Square Propagation): Designed for non-stationary environments, RMSProp adapts the learning rate based on the magnitude of recent gradients, helping to avoid the issue of vanishing or exploding gradients.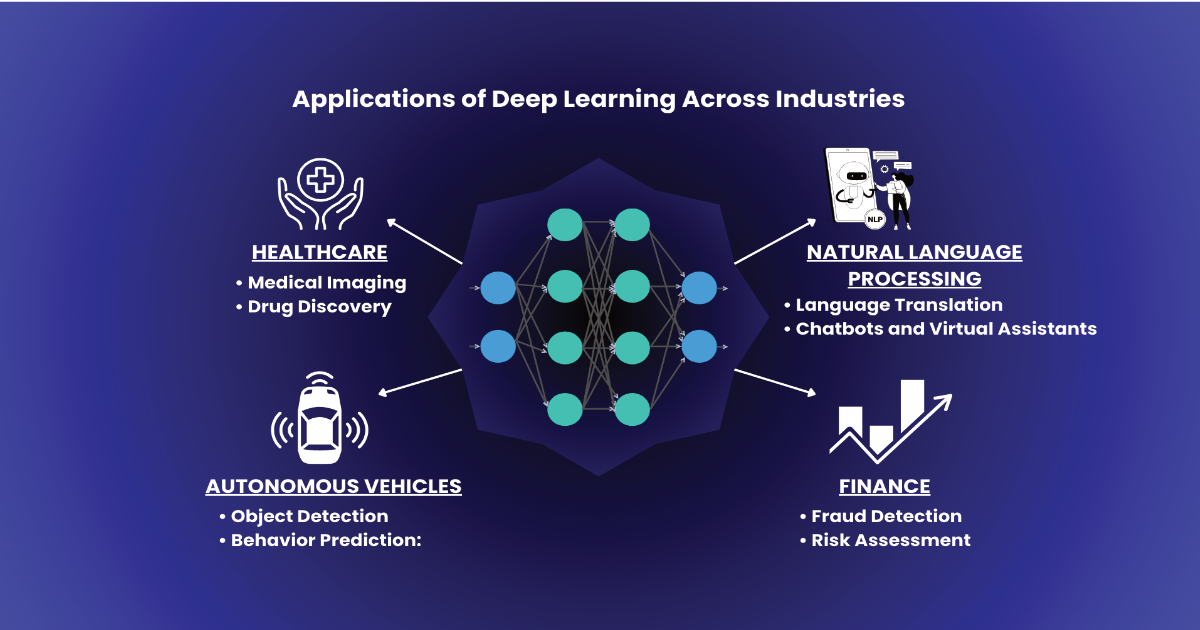
Applications of Deep Learning Across Industries
Deep learning has vast applications across industries, revolutionizing how organizations process data, make decisions, and solve complex problems. Here are some key sectors where deep learning is making a significant impact:
1. Healthcare
In healthcare, deep learning is being used to analyze medical images, predict disease progression, and assist in diagnosis. For example:
• Medical Imaging: CNNs are widely used in radiology to detect abnormalities in medical images such as MRIs, X-rays, and CT scans. These models can identify patterns that may be difficult for human eyes to detect, improving early diagnosis of diseases like cancer.
• Drug Discovery: Deep learning models are employed in drug discovery to predict how different compounds will interact with biological systems. These models help accelerate the identification of promising drug candidates.
2. Autonomous Vehicles
Deep learning is a cornerstone of self-driving car technology. It is used to process the vast amount of data collected by sensors and cameras, enabling autonomous vehicles to perceive their environment, make decisions, and navigate safely.
• Object Detection: CNNs are used to detect and classify objects such as pedestrians, vehicles, and traffic signs, helping the car avoid obstacles and adhere to traffic laws.
• Behavior Prediction: RNNs are used to predict the behavior of other road users, allowing the vehicle to make proactive decisions.
3. Natural Language Processing (NLP)
Deep learning has revolutionized NLP, allowing machines to comprehend and generate human language. Applications of NLP include:
• Language Translation: Deep learning models like Google’s BERT and OpenAI’s GPT have revolutionized machine translation, providing more accurate translations between languages by understanding context and syntax.
• Chatbots and Virtual Assistants: NLP-powered chatbots like Siri and Alexa use deep learning to process spoken language, understand queries, and provide relevant responses.
4. Finance
In the finance sector, deep learning is used for a range of applications, including fraud detection, stock market prediction, and algorithmic trading.
• Fraud Detection: Deep learning models can analyze transaction patterns and detect anomalies that may indicate fraudulent activities.
• Risk Assessment: Deep learning is also used to assess creditworthiness by analyzing a vast array of financial and behavioral data points, providing a more accurate risk profile.
The Future of Deep Learning
As deep learning continues to evolve, its potential applications and impact will only expand. Here are some key trends and future directions for the field:
1. Improved Interpretability
One of the challenges with deep learning models is their lack of interpretability. These models often operate as “black boxes,” making it difficult to understand how they arrived at a specific decision. Future research is focused on making deep learning models more transparent and explainable, particularly in high-stakes fields like healthcare and law.
2. Integration with Edge Computing
As the demand for AI applications grows, there is increasing interest in deploying deep learning models on edge devices (such as smartphones and IoT devices). This would allow real-time processing of data without needing to rely on cloud servers, improving latency and reducing bandwidth usage.
3. Multimodal Learning
Multimodal learning involves training models on multiple types of data (e.g., text, images, audio) simultaneously, enabling them to understand complex scenarios that involve more than one data modality. This approach could lead to significant advancements in areas like autonomous systems, healthcare, and multimedia content generation.
4. Ethical Considerations
As deep learning becomes more powerful, ethical considerations such as bias, fairness, and privacy will become increasingly important. Ensuring that deep learning models are trained on diverse and unbiased datasets will be crucial in preventing discriminatory outcomes.
Conclusion
Deep learning has transformed the landscape of AI and machine learning, enabling breakthroughs in fields ranging from healthcare to finance to autonomous vehicles. Its ability to learn from vast amounts of data and recognize patterns that are often invisible to humans has made it an indispensable tool for solving complex problems.
For businesses and industries, the continued integration of deep learning into operations will lead to new efficiencies, innovations, and capabilities. As we move forward, staying informed about deep learning’s advancements and ensuring ethical and transparent implementation will be critical for leveraging its full potential.


