
Machine learning (ML) models have become a cornerstone of modern technology, powering advancements across industries from healthcare to finance, retail, and beyond. These models enable systems to learn from data and make predictions or decisions without being explicitly programmed. Understanding the types of machine learning models is crucial for leveraging their capabilities in various applications. This article provides an in-depth look at the primary categories of machine learning models, their characteristics, and when they are typically used.
Overview of Machine Learning Models
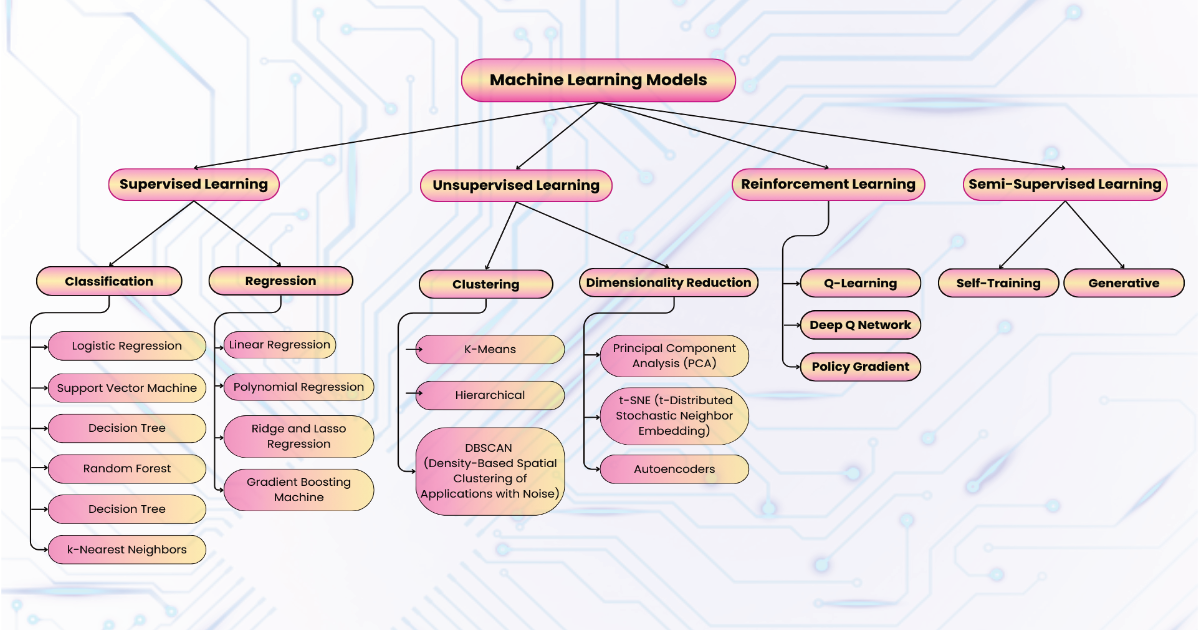
Machine learning models are broadly categorized into three main types based on how they learn from data: supervised learning, unsupervised learning, and reinforcement learning. Additionally, there is a fourth emerging category known as semi-supervised learning, which combines aspects of both supervised and unsupervised learning. These categories define how the algorithms interact with the data and the kind of problems they are designed to solve.
1. Supervised Learning: Models learn from labeled data.
2. Unsupervised Learning: Models identify patterns from unlabeled data.
3. Reinforcement Learning: Models learn through trial and error by interacting with an environment.
4. Semi-Supervised Learning: Models use a small amount of labeled data and a large amount of unlabeled data to improve learning accuracy.
Now, let’s explore each of these categories in more detail and the specific types of machine learning models under them.
1. Supervised Learning Models
Supervised learning models are the most commonly used machine learning models. They rely on a dataset that contains both inputs and known outputs (labeled data). The goal is to learn a function that maps the inputs to the correct output. Supervised learning models are particularly useful for tasks where historical data exists and predictions need to be made based on that data.
Supervised learning models can be further divided into two subcategories: classification and regression.
A. Classification Models’
Classification models are used when the output variable is categorical, meaning that the model must assign an input to one of several predefined classes or categories. Examples include spam detection (spam or not spam), image recognition (dog, cat, or bird), and credit risk assessment (low risk, medium risk, or high risk).
i) Logistic Regression
Despite its name, logistic regression is a classification model used to predict binary outcomes. It estimates the probability that a given input belongs to a particular class by using the logistic function. Logistic regression is widely used in problems where the output is binary (e.g., yes/no, 0/1). It is simple, efficient, and interpretable, making it a popular choice for many real-world applications like fraud detection and medical diagnoses.
How it works:
- Logistic regression calculates the weighted sum of the input features.
- The result is passed through the sigmoid function, which outputs a probability value between 0 and 1.
- If the probability exceeds a certain threshold (commonly 0.5), the model assigns the input to one class (e.g., positive class); otherwise, it assigns it to the other class (e.g., negative class).
Use cases:
- Medical diagnosis: Predicting whether a patient has a disease based on medical features.
- Spam detection: Identifying and categorizing emails as either spam or legitimate.
ii) Support Vector Machines (SVM)
Support Vector Machines are powerful classification algorithms that aim to find the hyperplane that best separates different classes in a dataset. SVM is particularly useful in high-dimensional spaces where the number of features exceeds the number of data points. By maximizing the margin between the classes, SVM offers robust classification performance, even in complex datasets. SVM can also be extended to non-linear classification through the use of kernel functions.
How it works:
- SVM tries to find the hyperplane that maximally separates the data points of different classes in the feature space.
- For non-linearly separable data, SVM uses kernel functions (such as the radial basis function, or RBF) to project the data into a higher-dimensional space where a separating hyperplane can be found.
Use cases:
- Text classification: Sorting text into categories like positive or negative sentiment..
- Image classification: Distinguishing between different objects in images.
iii) Decision Trees
A decision tree is a simple, yet highly effective classification model that splits the data into different branches based on feature values. Each node in the tree represents a decision point, and the branches represent the outcomes. Decision trees are simple to interpret and visualize, making them ideal for explaining model decisions to stakeholders. They can, however, be prone to overfitting, particularly when the tree becomes too deep and complex.
How it works:
- The model splits the data based on the values of input features at each node.
- At each step, it selects the feature that results in the best split, often measured by metrics like Gini impurity or information gain.
- The tree continues splitting the data until a stopping criterion is met, such as reaching a maximum depth or having a small number of samples in a node.
Use cases:
- Customer segmentation: Classifying customers into different segments based on demographics and behavior.
- Loan approval: Predicting whether a loan should be approved or rejected based on financial data.
iv) Random Forest
Random Forest is an ensemble method that builds multiple decision trees and combines their outputs to make a final prediction. By averaging the results of many trees, Random Forest reduces overfitting and improves the model’s generalization ability. It is widely used in tasks like classification of images, text, and various biological data.
How it works:
- Each tree in the Random Forest is trained on a random subset of the training data and uses a random subset of features at each split.
- For classification tasks, the final prediction is made based on the majority vote from all the trees in the forest.
Use cases:
- Fraud detection: Identifying fraudulent transactions in financial data.
- Healthcare: Predicting disease outcomes or patient readmission rates.
v) k-Nearest Neighbors (k-NN)
k-NN is a simple, instance-based classification algorithm that makes predictions based on the majority class of the k closest data points (neighbors). Despite its simplicity, k-NN can be highly effective in certain contexts. It is, however, computationally expensive when dealing with large datasets because it requires searching through the entire dataset to make a prediction.
How it works:
- For a given input, the algorithm finds the k closest training data points (neighbors) in the feature space.
- It assigns the most common class among these neighbors to the input data point.
Use cases:
- Recommendation systems: Recommending products to users based on the preferences of similar users.
- Pattern recognition: Classifying images or recognizing speech patterns.
B. Regression Models
Regression models are applied when the output variable is continuous.. The goal is to predict a numerical value based on input features. Regression is applied in areas like stock price prediction, real estate valuation, and demand forecasting.
i) Linear Regression
Linear regression is one of the simplest and most interpretable models in machine learning. It assumes a linear correlation between the input variables and the target variable. The model fits a line that best approximates the relationship between the input and output. Despite its simplicity, linear regression is highly effective for problems with an approximately linear relationship between variables, such as predicting house prices or sales.
How it works:
- The model calculates a linear combination of the input features and weights.
- It fits the best-fitting line that minimizes the sum of squared differences between the predicted and actual values.
Use cases:
- Housing market analysis: Predicting the price of a house based on its features (e.g., size, location).
- Sales forecasting: Estimating future sales based on historical sales data.
ii) Polynomial Regression
Polynomial regression extends linear regression by modeling the relationship between the independent and dependent variables as an nth-degree polynomial. This type of regression is useful for modeling non-linear relationships. While it adds complexity, it can capture more intricate patterns than linear regression.
How it works:
- The model fits a polynomial equation to the data, allowing for more complex relationships than a straight line.
- The degree of the polynomial determines how flexible the model is in capturing non-linear patterns.
Use cases:
- Market trend analysis: Modeling complex trends in stock prices or demand for products.
- Economics: Modeling the relationship between GDP and various factors over time.
iii) Ridge and Lasso Regression
Ridge and Lasso are regularized versions of linear regression, designed to prevent overfitting by adding a penalty term to the loss function. Ridge regression uses L2 regularization, which shrinks the coefficients by minimizing their square. Lasso regression uses L1 regularization, which can force some coefficients to be exactly zero, effectively performing feature selection. Both techniques are valuable when dealing with high-dimensional data.
Use cases:
• High-dimensional data: Handling datasets with a large number of features, such as genetic data.
• Financial modeling: Predicting stock prices while avoiding overfitting to noisy data.
iv) Gradient Boosting Machines (GBM)
Gradient Boosting is a powerful technique for both regression and classification problems. It builds an ensemble of weak learners (usually decision trees) in a sequential manner, with each new tree attempting to correct the errors made by the previous trees. Gradient Boosting is particularly effective for problems with complex, non-linear relationships.
How it works:
- The model builds weak learners in a sequential manner, with each new learner correcting the mistakes made by the previous ones.
- The final prediction is obtained by combining the outputs of all the weak learners.
Use cases:
- Credit scoring: Predicting the likelihood of defaulting on a loan.
- Marketing: Predicting customer responses to marketing campaigns.
2. Unsupervised Learning Models
Unsupervised learning models work on data without labeled outputs. The objective is to reveal hidden patterns or structures within the data. Unsupervised learning is commonly used for exploratory data analysis, clustering, and dimensionality reduction.
A. Clustering Models
Clustering is a type of unsupervised learning used to group similar data points together. These models are often used in market segmentation, image compression, and anomaly detection.
i) k-Means Clustering
k-Means is among the most popular clustering algorithms.. It partitions the data into k clusters by minimizing the variance within each cluster. The algorithm iteratively assigns data points to the nearest cluster center and updates the center’s position. k-Means is simple and scalable but may struggle with non-convex clusters.
ii) Hierarchical Clustering
Hierarchical clustering builds a hierarchy of clusters either from the bottom up (agglomerative) or from the top down (divisive). It does not require the user to specify the number of clusters beforehand and creates a dendrogram, which can be used to visualize the data’s hierarchical structure. This method is useful when the goal is to uncover the nested relationships between clusters.
iii) DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN is a density-based clustering algorithm that groups data points based on their density in the feature space. It is particularly useful for identifying clusters of arbitrary shapes and is robust to noise, making it a great option for tasks like anomaly detection. Unlike k-Means, DBSCAN does not require the number of clusters to be defined in advance.
B. Dimensionality Reduction Models
Dimensionality reduction techniques aim to decrease the number of features in a dataset while retaining as much information as possible. These models are essential when dealing with high-dimensional data, as they can simplify models, reduce computational costs, and prevent overfitting.
i) Principal Component Analysis (PCA)
PCA is a linear dimensionality reduction technique that transforms the data into a set of uncorrelated variables called principal components. These components are ranked according to the amount of variance they capture in the data. PCA is widely used for visualizing high-dimensional data and as a preprocessing step in many machine learning pipelines.
ii) t-SNE (t-Distributed Stochastic Neighbor Embedding)
t-SNE is a non-linear dimensionality reduction technique used primarily for visualizing high-dimensional data. It reduces the dimensionality of the data while preserving its local structure, making it particularly useful for exploring complex datasets. t-SNE is often used in the fields of bioinformatics, image recognition, and natural language processing.
iii) Autoencoders
Autoencoders are a type of neural network used for unsupervised learning tasks, specifically for dimensionality reduction and feature learning. They consist of an encoder that compresses the input into a lower-dimensional representation and a decoder that reconstructs the input from this representation. Autoencoders are widely used in tasks like image denoising, anomaly detection, and data compression.
3. Reinforcement Learning Models
Reinforcement learning (RL) models operate in an environment where an agent takes actions to maximize cumulative rewards over time. Unlike supervised learning, where the model learns from a static dataset, reinforcement learning involves learning through trial and error by interacting with the environment. RL is widely used in fields like robotics, game playing, and autonomous systems.
a) Q-Learning
Q-Learning is a popular reinforcement learning algorithm that learns the value of actions in a given state by estimating a “Q-value” for each action-state pair. It aims to maximize the total reward over time by following an optimal policy derived from these Q-values. Q-Learning is used in applications like robotic control and game AI, where the agent must learn to navigate complex environments.
b) Deep Q-Networks (DQN)
Deep Q-Networks integrate Q-Learning with deep neural networks to effectively manage high-dimensional state spaces. Instead of maintaining a table of Q-values, DQN uses a neural network to approximate the Q-value function, allowing it to scale to more complex environments. DQN has been famously applied in video game playing, where it surpassed human-level performance on several Atari games.
c) Policy Gradient Methods
Policy gradient methods directly optimize the policy that the agent uses to select actions. Unlike value-based methods like Q-Learning, policy gradient methods do not require the estimation of a value function. They are often used in environments with continuous action spaces, such as robotic manipulation and autonomous driving. An example of a policy gradient algorithm is the
Proximal Policy Optimization (PPO), which has been widely adopted in advanced RL applications.
4. Semi-Supervised Learning Models
Semi-supervised learning is a hybrid approach that integrates a small set of labeled data with a larger set of unlabeled data. This method is especially useful when labeling data is expensive or time-consuming. Semi-supervised learning is used in various applications like web content classification, speech recognition, and medical imaging.
a) Self-Training
Self-training is a simple semi-supervised learning technique where a supervised learning model is first trained on the labeled data. It then makes predictions on the unlabeled data and iteratively incorporates the most confident predictions into the training set. This method is useful in cases where acquiring labeled data is expensive, such as in medical diagnoses.
b) Generative Models
Generative models like Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) can also be used for semi-supervised learning. These models generate synthetic data or representations from the unlabeled data, improving the model’s performance on the labeled task. GANs, in particular, have been used to generate realistic images, while VAEs are commonly applied in text and image processing tasks.


